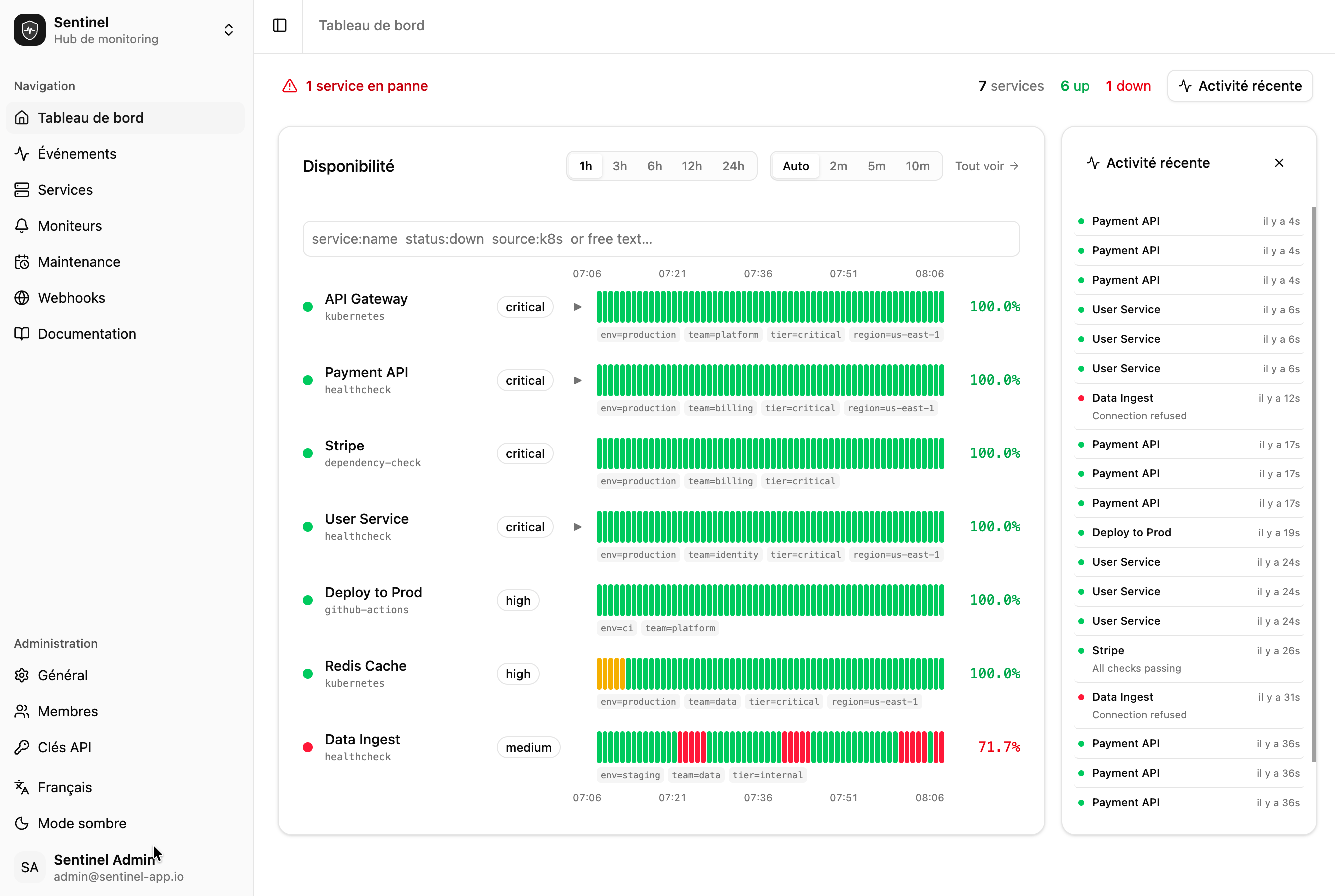
Tout ce qu'il faut pour garder le contrôle
Simple par design. Puissant quand il le faut.
Alertes instantanées
Soyez notifié sur Slack, email ou webhook dès qu'un service se dégrade ou tombe.
Source-Agnostique
Acceptez des signaux de n'importe quel système — CI, cron, Prometheus, Grafana, scripts custom. Un seul endpoint, toutes les sources.
Auto-Découverte
Les services sont créés automatiquement au premier signal. Aucune configuration manuelle.
Labels & Scoping Dynamique
Taggez vos services automatiquement depuis les métadonnées des signaux. Définissez la priorité à l'ingestion. Scopez vos monitors par labels au lieu de listes de services.
Suivi SLA (bientôt)
Définissez des engagements d'uptime et suivez la conformité. Gardez un œil sur votre budget d'erreur.
Comment ça marche
Trois étapes. Aucun agent à installer.
Envoyez
Poussez des signaux de santé depuis n'importe quel système via un seul endpoint API ou webhook.
Soyez alerté
Sentinel détecte les changements de statut et vous notifie instantanément via Slack, email ou webhook.
Suivez dans le temps
Surveillez l'uptime dans le temps et identifiez les tendances avant qu'elles ne deviennent des incidents.
Monitoring Kubernetes natif
Déployez l'opérateur une fois. Annotez vos workloads. Sentinel s'occupe du reste.
Santé des workloads, pas le bruit des pods
Monitore les Deployments, StatefulSets et DaemonSets directement. Rapporte la santé basée sur les replicas ready vs desired — pas les événements individuels de pods.
Détection des rolling updates
Sait quand un rollout est en cours et le rapporte en métadonnée. Pas de fausses alertes pendant les déploiements.
Trois états de santé
Up (tous les pods ready), Degraded (disponibilité partielle), Down (aucun pod ready). Suivi dans le temps avec historique d'uptime.
Services multi-composants
Plusieurs workloads avec le même slug de service sont suivis comme composants. Dépliez la barre d'uptime pour voir la santé par composant.
Installer l'opérateur
helm install sentinel-operator \
oci://ghcr.io/sentinel-app-io/charts/sentinel-operator \
--namespace sentinel --create-namespace \
--set credentials.sentinelUrl=https://app.sentinel-app.io \
--set credentials.keyId=your-key-id \
--set credentials.secret=your-secretAnnoter vos workloads
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment-api
annotations:
sentinel.io/monitor: "true"
sentinel.io/service: "payment-api"
# sentinel.io/component: "api" # optional overrideEnvoyez un signal dans n'importe quel langage
Un seul endpoint, n'importe quel langage. Rapportez la santé de vos services en un appel HTTP.
curl -X POST https://app.sentinel-app.io/api/v1/signals/ \
-H "Content-Type: application/json" \
-H "STNL-Access-Key: $KEY_ID" \
-H "STNL-Secret-Key: $SECRET" \
-d '{"service": "my-api", "status": 1}'Fonctionne avec tout langage capable de faire des requêtes HTTP. Consultez la documentation pour plus d'exemples.
Des tarifs simples et transparents
Gratuit pour commencer. Évoluez selon vos besoins.